カルチャー
働く人々
事業
テクノロジー
キャリア登録
採用情報
トップ
テクノロジー
TiDB on AWS EKS 〜DMM動画のPoCレポート〜
テクノロジー
2021.12.12
TiDB on AWS EKS 〜DMM動画のPoCレポート〜
アドベントカレンダー2021
シェア
アドベントカレンダー2021
関連する記事
テクノロジー
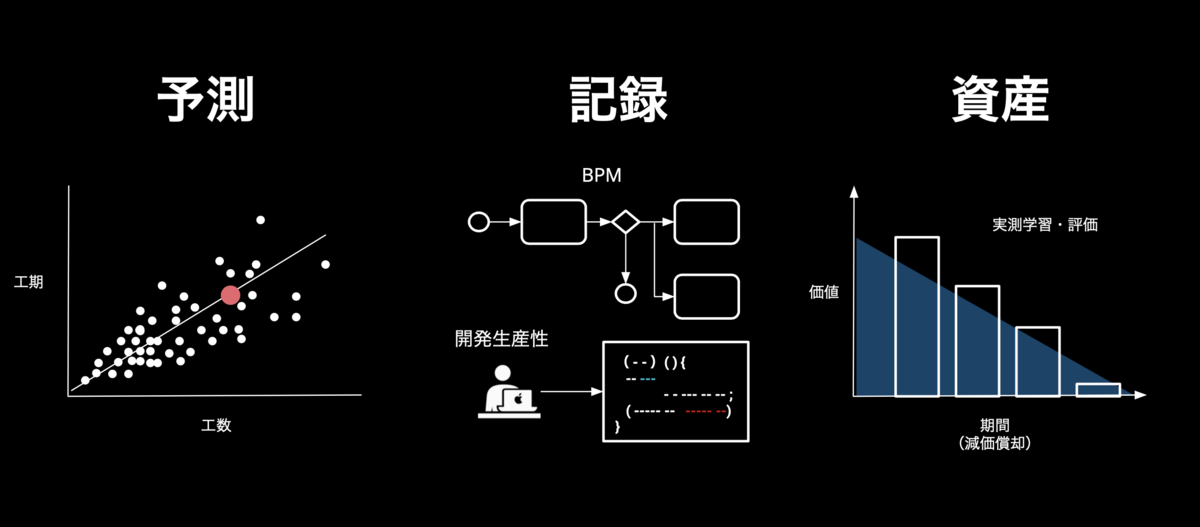
ソフトウェア開発の予測と記録と資産〜プロジェクト失敗率 69%の壁〜
PM
PdM
開発プロセス
アドベントカレンダー2021
テクノロジー
DMM.comのクリエイティブな組織への取り組みとVPoEの役割について
アドベントカレンダー2021
テクノロジー
ソフトウェアエンジニアがエニグマを解説してみる
セキュリティ
アドベントカレンダー2021
テクノロジー
プロダクトデザインや組織創設を通して感じたDMMとは
横断開発
UX
プロダクトデザイン
デザイン
アドベントカレンダー2021